@tool decorator to expose them to Orchestrate.
Each Python tool runs inside an isolated container with its own virtual environment. This design keeps your code and dependencies separate from the host operating system, so you work in a secure and consistent runtime while focusing on your agent’s goal.
Python tool example
Python
- Use Google-style docstrings to apply descriptions and document the Python tool.
- For compute/memory capabilities of the containers in which the python tools run.
Auto-discover
The ADK can convert ordinary Python files into Python tools that are ready to be uploaded to Orchestrate. The process automatically imports and adds a@tool decorator and generates a docstring for functions in the source file.
For docstring generation, an LLM is invoked, so the command requires an environment (.env) file with valid credentials for Groq, watsonx, or Orchestrate.
To convert a Python file, use the following command:
BASH
- The
auto-discoverfeature is standalone but also bundled with the import process. - This option takes all the flags of the standalone
auto-discovercommand except--output. - The ADK runs the auto-discover process and uploads the results instead of writing to a file.
- If you are using AI Gateway, the model name must start with virtual-model or virtual-policy and you must pass it with the —llm flag.
- The auto import process does not support toolkit imports. To complete your import, generate the output file and then run the toolkit import command.
Importing Python-based tools
You can import Python-based tools in two forms: as an individual tool or as a toolkit. When you import a tool as an individual tool, you add a single Python tool to watsonx Orchestrate and manage it independently. When you import tools as a toolkit, you group multiple Python tools into one toolkit and manage them together as a single unit.Choosing between standalone tools and toolkits:The choice between standalone Python tools and Python toolkits significantly impacts performance and operational characteristics:Standalone Python tools:
- Process-per-invocation model (~100-300ms overhead per call)
- Supports non-thread-safe operations
- Suitable for infrequent calls or prototyping
- Shared process model (no process overhead after startup)
- Requires thread-safety
- Better performance for frequently called tools
- Dedicated resources in live premium environments
- Importing Python toolkits
- Importing individual Python tools
After you create your Python tools, import them as a Python toolkit. A Python toolkit groups related tools so you can deploy and run them together in a single Python process. To meet this goal, design every tool in the toolkit to be thread-safe and reentrant. This approach gives you faster execution because the tools share the same process.When you run Python tools outside a toolkit (as standalone Python tools), the system starts a lightweight process each time the tool runs. This design supports tools that use non-thread-safe operations, but it increases execution time by approximately 100-300ms per invocation compared to a toolkit.To create a Python toolkit, place all required Python tools in one folder. Each tool can include one or more Python files. In those files, define your functions and apply the For the YAML file, configure the following:Example:
When to use Python toolkits vs standalone Python tools:
- Use Python toolkits when you have multiple related tools that are thread-safe, called frequently, or share dependencies
- Use standalone Python tools when tools use non-thread-safe operations, are called infrequently, or need process isolation
@tool decorator so watsonx Orchestrate exposes each function as a usable tool.You can place tools that multiple agents use into a single toolkit. When you update tools inside a toolkit, redeploy all related agents to the live environment so you use the updated versions. Choose the number of tools in each toolkit based on the level of concurrent requests you expect. For more information, see CPU and memory allocation for Python toolkits.CPU and memory allocation for Python toolkits
Draft environment:- All imported Python toolkits and Python tools run in a single Kubernetes deployment container per tenant
- Process overheads per tool call exist in draft (approximately 100-300ms per invocation)
- Container resources: 2 vCPUs, 2 GB of memory, and 5 workers
- Deployment supports two replicas
- You can import up to five Python toolkits per tenant
- Each toolkit runs in its own dedicated Kubernetes deployment container
- No process overheads per tool call - tools run in a persistent process
- Container resources per toolkit: 2 vCPUs, 2 GB of memory, and 5 workers
- Each deployment supports two replicas
- Supports up to 10 concurrent requests per toolkit (5 workers × 2 replicas)
- Similar to draft environment with shared container model
- Contact support to request premium access for dedicated toolkit containers
Add Python toolkits using the ADK CLI
Use theorchestrate toolkits add command to add a Python toolkit.BASH
Import Python toolkits from a file
You can also import a Python toolkit from a YAML file. This file defines the same configuration options as the add command and fits well into import scripts and CI/CD pipelines.Use theorchestrate toolkits import command to import a toolkit from a file.BASH
The version of the YAML specification.
The type of toolkit. For Python toolkits, use
python.The name of the toolkit.
The description of the toolkit.
Key-value pairs for the toolkit.
toolkit_name.yaml
Thread-safety requirements
All tools in a Python toolkit must be thread-safe because they run in a shared process with concurrent requests. A tool is thread-safe when multiple threads can call it simultaneously without causing race conditions or data corruption.Thread-safe patterns:- No global mutable state
- Use immutable data structures
- Employ proper async/await patterns
- Use thread-safe libraries
- Global variables that change
- File system writes
- Non-thread-safe libraries
- Shared database connections without pooling
Additional features of Python tools
Adding Dependencies
Adding Dependencies
If your Python function relies on external libraries or packages, specify these dependencies in the Python tool examplerequirements.txt exampleEnterprise requirements.txt with private registry (Example only, not actual URL)When importing your tool, specify the requirements.txt file by using the -r flag.
requirements.txt file to make sure your tool runs correctly.When you import Python-based tools, watsonx Orchestrate validates all packages against a tenant-specific Python package allowlist. This validation limits installations to approved packages only.During import, watsonx Orchestrate verifies each dependency and version in requirements.txt against the allowlist. If the allowlist lacks a required package or the exact version you specify, the import fails. watsonx Orchestrate runs this validation only at import time. To add or update allowed Python packages, configure the Python tool allowlist through the API. Fore more information see Package Configuration.To complete a successful import, follow these rules:- Declare every dependency in requirements.txt.
-
Pin each dependency to an exact version, using this format:
Use this format in:requirements.txt
requirements.txt- The tenant allowlist configuration
- Add all transitive dependencies to the allowlist.
Notes:
- watsonx Orchestrate does not revalidate tools that you already imported when the allowlist changes.
- When allowlist validation is enabled and the allowlist is empty, you cannot use any Python packages.
- Removing all packages from the allowlist does not turn off validation.
Python
TEXT
TEXT
For more information on the format of a requirements file, see the official pip documentation. For enterprise patterns including Artifactory configuration and hash-based verification, see Python dependency management.
BASH
Using complex input and output argument types with Pydantic
Using complex input and output argument types with Pydantic
Python tools support input and output arguments based on the following types:
- any native Python type from the
typingspackage - classes which extend
BaseModelfrom the popular library Pydantic EnumtypesNaNandInfinityvalues- Dataclasses
- Custom objects with
__dict__attribute
PYTHON
Securely providing credentials
Securely providing credentials
Python tools are compatible with the watsonx Orchestrate Connections framework. A connection represents a dependency on an external service
and are a way to associate credentials to a tool such as those for Basic, Bearer, API Key, OAuth, or IDP SSO based authentication flows. Python tools also support
key_value connections which as the name implies are arbitrary dictionaries of keys and values which can be used to pass in
credentials for any authorization scheme which does not match one of the existing native schemes.Connections are referenced by something known as an application id (or app_id). This app_id is the unique identifier of a connection.
OpenAPI connections can have at most one Connection’s app_id associated to them.For more information, see Connections, and the expected_credentials input to the @tool annotation.Creating multi-file Python tool packages
Creating multi-file Python tool packages
In addition to importing a single tool file, it is possible to import an entire folder (package) along with your tool file.
This is useful when you wish to centralize logic into shared utility libraries, for example, shared authentication, data processing, or including static files such as CSVs or sqlite databases.Assuming a folder structure as follows:my_tool.py:Importing your multi-file Python tool:
Assuming your CLI was currently in theLimitations:
PYTHON
Assuming your CLI was currently in the
my_agentic_project folder, this tool could be imported using the following:BASH
Notes:
- Only tools defined in
my_tool.pywill be imported. Other Python files in the package will not be scanned for tools. - The system will only accept strings composed of alphanumeric characters and underscores (
_) in thenameattribute of the@tooldecorator inmy_tool.py. - The system will only accept tool file names composed of alphanumeric characters and underscores (
_). - The package root folder and the tool file path CLI arguments MUST share a common base path.
- The path of the tool file folder relative to the package root folder, must be composed of folder names which are only composed of alphanumeric characters and underscores (
_). - Any whitespace like characters which prefix or suffix provided package root path will be stripped by the system.
- A package root folder path that resolves to an empty string will make the system assume that no package root was specified. Then, the system falls back to single Python file tool import.
- The max compressed tool size: 50Mb
- File resolution for non-python packages must be done relative to the current file, as seen above
- Imports to packages within your code must be resolved relatively
Creating tools that accept files
Creating tools that accept files
You can create Python tools that accept files or return files to download.To do that, you must comply with the following requirements:Use the
The
Use the
Use this approach when a tool only needs file metadata or to read the content on demand.
It helps reduce processing overhead and improves performance.
- To accept files as input, the tool must accept a sequence of bytes as arguments.
- To return a file for download, the tool must return a sequence of bytes as output.
Python
WXOFile parameter type when a tool must reference a file without processing its full content.The
WXOFile class provides methods to retrieve file properties or content as needed.You can call the following methods:get_file_name(url: str) → str | None
get_file_name(url: str) → str | None
Returns the filename stored in S3 user metadata.Parameters:Returns:
The file URL.
string
The file name.
get_file_size(url: str) → int | None
get_file_size(url: str) → int | None
Returns the file size in bytes from S3 user metadata.Parameters:Returns:
The file URL.
string
The file size in bytes.
get_file_type(url: str) → str | None
get_file_type(url: str) → str | None
Returns the MIME type stored in S3 user metadata.Parameters:Returns:
The file URL.
string
The file MIME type, such as
image/jpeg or text/plain.get_content(url: str) → bytes
get_content(url: str) → bytes
Downloads the file and returns its content.Parameters:Returns:
The file URL.
bytes
The file content in bytes.
MultiFileConstraints class with WXOFile to set limits and validation rules for selecting or uploading multiple files.It includes these attributes:Attributes
Attributes
Minimum number of files required.
Default: 1
Maximum number of files allowed.
Default: 100
Max size per file in bytes.
The limit is 30 MB (31,457,280 bytes).
Total size across all files.
The limit is 30 MB (31,457,280 bytes).
If omitted but max_size_per_file is provided, it auto‑computes:
Allowed file extensions. For example:
.pdf, .png.Optional UI text hint.
It helps reduce processing overhead and improves performance.
The method
get_file_metadata(url: str, session_id: str) -> str is deprecated for single‑file uploads.- Single-File upload
- Multi-File upload
Python
Creating tools that return inline tables, images or links
Creating tools that return inline tables, images or links
The native watsonx Orchestrate web chat supports Markdown rendering. To ensure correct formatting, the LLM can be instructed to return output in Markdown. In some cases, however, it is more efficient for the tool to return the expected output directly, reducing the amount of transformation required by the LLM.Inline tables
Links
Images
PYTHON
PYTHON
PYTHON
Using Context Variables
Using Context Variables
If your agent has access to context variables, provided either by the default context or by passing context with the request, you can use these variables within your Python tool.To do this you will need to pass an Update context variables:
AgentRun object parameter to the Python tool:Get context variables:Python
Python
Note:
- A tool can only have one
AgentRunparameter, a tools with more than one will fail to import. For more information about providing context to agents, see Providing access to context variables - You cannot update the default context variables offered by watsonx Orchestrate.
- Context persistence: Updated context variables are only available within a single run invocation. They are not persisted across chat sessions or threads. If multiple tools are called during the same run, all tools will receive the updated context. For subsequent runs, you must explicitly pass the updated context from the previous run to maintain state.
Dynamic input and output schemas
Dynamic input and output schemas
In integration-heavy environments, schemas change frequently. Dynamic input and output schemas enable select fields in a tool’s input to be mutable at runtime—securely and predictably—without affecting immutable core fields.Use dynamic it when:
- You need to add new attributes to objects (e.g., CRM records).
- You need a small number of user-defined fields beyond a stable core API.
- You want Builder UI users to change types (e.g., string → number) for dynamic fields only.
- All fields are stable and tightly coupled to a known data model.
- You need complex nested modifications (Phase 1 supports flat properties only in most scenarios).
Python
Python
Creating tools that can trigger citations
Creating tools that can trigger citations
Create tools that trigger citation generation so Agents provide source references in their responses. Use the Artifact attributes:
ToolResponseFormat.CONTENT_AND_ARTIFACT response format and return both the main content and an artifact that contains citation data.Example:Python
A list of search result objects that support citation creation. Each object includes:
- title (string): Title of the source.
- body (string): Content or excerpt from the source.
Controls how many citations to display.
- Use -1 to show every citation (default).
- Use 0 or a positive number to limit the count.
Creating a form tool
Creating a form tool
Create a tool that returns a form with interactive widgets to collect structured input from users. Define the form by using
FormWidget and input components such as TextInput and DatePicker. Return the form through a ToolResult so it renders in the user interface.For more information, see Tool response and annotations.Show Form Fields
Show Form Fields
TextInput
TextInput
Use to gather basic textual information such as names and emails.
TextArea
TextArea
Use to gather long textual information.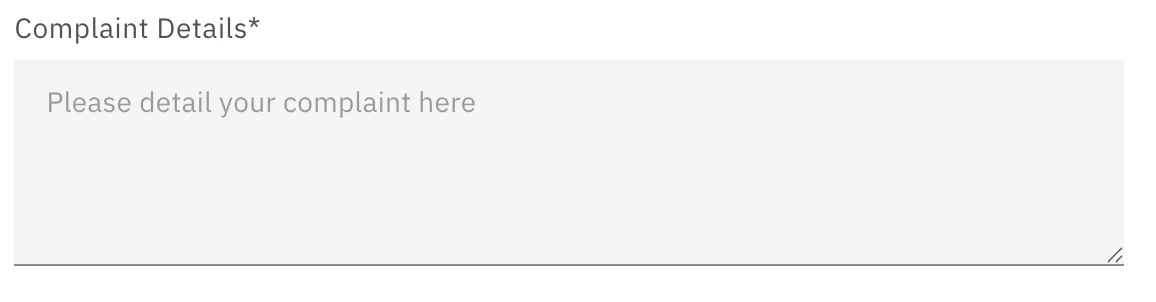
RadioButton
RadioButton
Use to gather a singular choice from a user.
Checkbox
Checkbox
Use to gather boolean choices from the user.
ComboBox
ComboBox
Dropdown field used for gathering a single user choice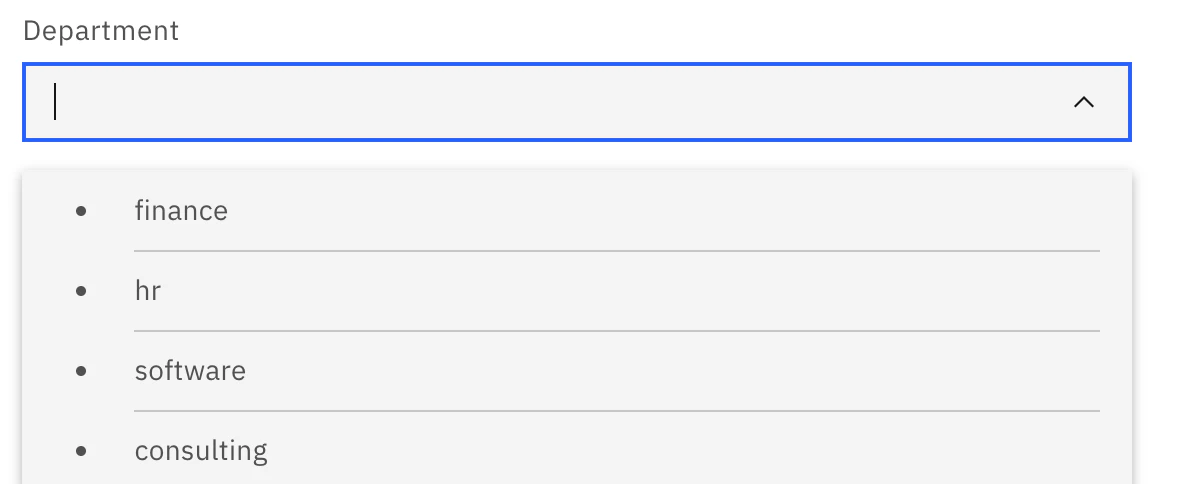
NumberInput
NumberInput
Use to gather numberical data from a user.
DatePicker
DatePicker
Use to gather an individual date from a user.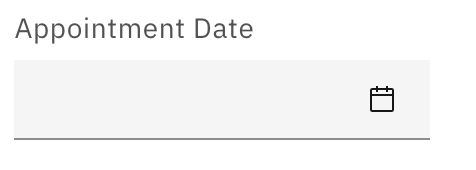
DateRangePicker
DateRangePicker
Use to gather a start and end date from a user.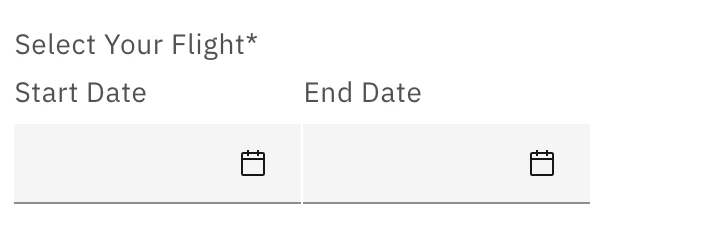
FileUpload
FileUpload
Use to gather file or files from a user.
FileDownload
FileDownload
Clickable button that downloads a file
- Use the same ADK version when importing tools to ensure compatibility.
- Reuse a common
requirements.txtacross multiple tools to reduce repeated virtual-environment setup. - If tools require conflicting package versions, maintain separate
requirements.txtfiles and environments.
Runtime and migration strategy
Python tools execute within a UV virtual environment inside a component called the tools runtime. This runtime includes a predefined set of supported Python versions. Currently, the only supported version is Python 3.12.Version Management
- When a tool is imported into the runtime, it uses the Python version it was originally imported with.
- If that version becomes deprecated by watsonx Orchestrate, the system will:
- Display a deprecation warning in the UI.
- Show the same warning when running the command:
BASH
- Inform the user that the tool must be reimported to remain compatible.
Deprecation Timeline
- After 24 months of deprecation:
- The runtime will remove support for the deprecated Python version.
- If the tool has not been reimported, the runtime will attempt to reimport it using the closest supported Python version.
Limitations of Python tools
Host networking
- watsonx Orchestrate Developer Edition: Python tools run inside a container. In this environment,
localhostrefers to the container itself, not the host machine. To call an endpoint on the host machine, usedocker.host.internalor the host machine’s IP address. - SaaS: The SaaS version of watsonx Orchestrate cannot access your company’s internal network. If internal access is required, prototype with the Developer Edition and then deploy watsonx Orchestrate on premises or consult IBM for alternative solutions.
- On premises: To allow a tool to access external internet resources, ensure that firewall rules do not block outbound traffic from the node pool responsible for tool execution.