Before you begin
To analyze your agent, you must first evaluate it. For more information, see Evaluating agents and tools.Analyzing
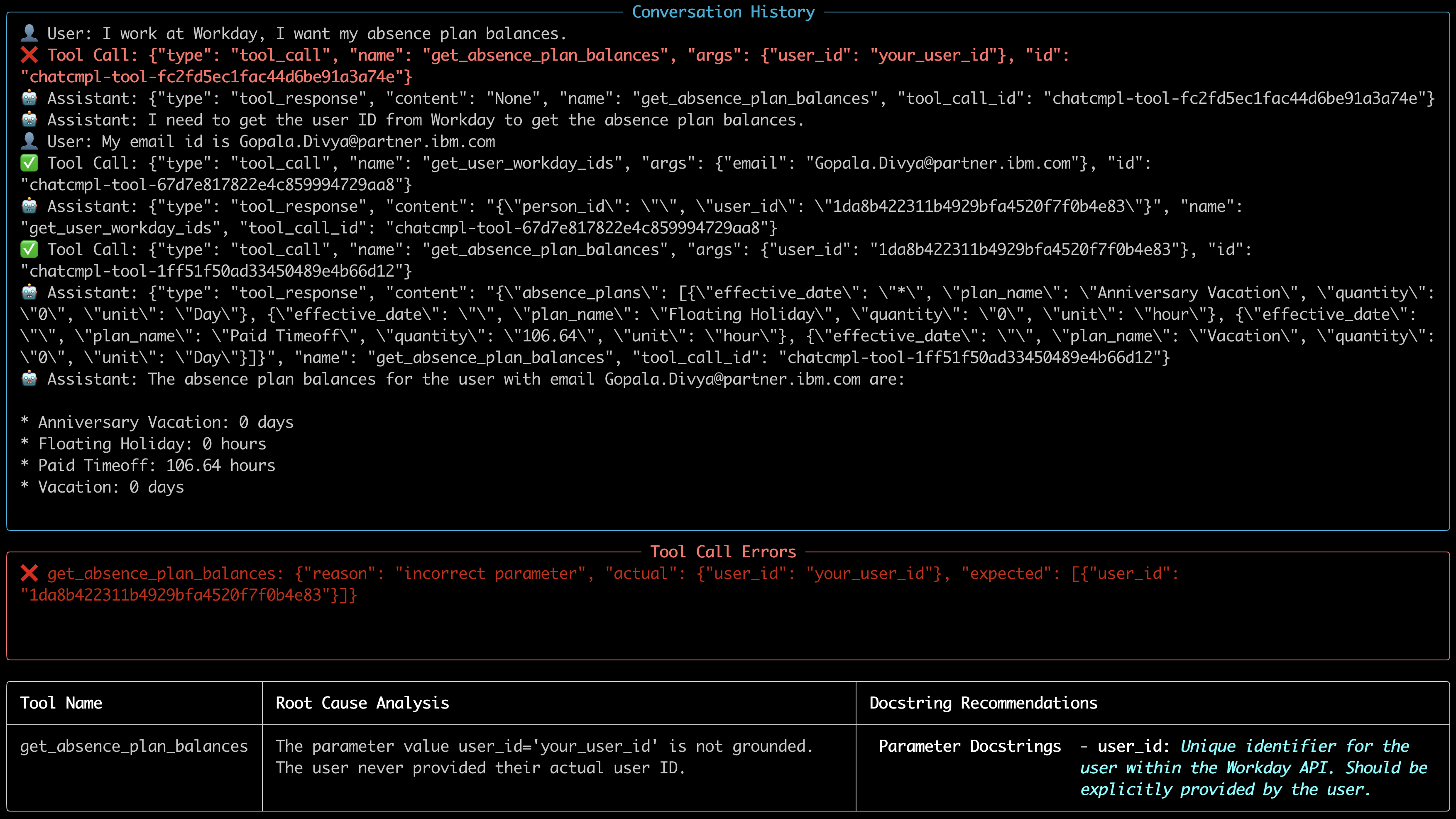
Theanalyze command provides a detailed breakdown of your agent evaluation results, highlighting where the agent succeeded, failed, and why. It generates an overview analysis for each dataset result in the specified directory, helping you quickly identify:
- Which tool calls were expected and made
- Which were irrelevant or incorrect
- Any parameter mismatches
- A high-level summary of the agent’s performance
- Missed tool calls
- Analysis Summary: Displays the overall evaluation type (e.g., Multi-run), total number of runs, number of runs with problems, and the overall status. This provides a quick high-level view of the evaluation results.
- Test Case Summary: Presents key counts for each test run, including expected vs. actual tool calls, correct tool calls, text match results, and journey success status.
- Conversation History: Step-by-step breakdown of every message exchanged, providing insight into where things went right or wrong.
- Analysis Results: Details the specific mistakes, along with the reasoning for each error (e.g., irrelevant tool calls).
BASH
Analyzing tools
Theanalyze command supports tool description quality analysis for failing tools in your workflows. This helps ensure that your tool definitions include clear and sufficient docstrings.
When you provide the --tools-path flag, the analyzer will:
- Inspect the Python source file containing your tool definitions.
- Evaluate the quality of each tool’s description (docstring).
- Display:
- A warning if the description is missing or classified as poor.
- An OK message if the description meets quality standards.
Note:
- Description quality analysis only runs for tools that failed during evaluation.
- For now, you can use only Python tools.
BASH
Example Output
Runninganalyze on the evaluation results of a dataset, such as examples/evaluations/analysis/multi_run_example, produces output like the following for both runs of data_complex.json: